Metoda nejbližšího souseda
Jak již víme z kapitoly o podobnostech a vzdálenostech ve vícerozměrném prostoru, metoda nejbližšího souseda definuje vzdálenost mezi skupinami a
jako
|
|
(1) |
Tento vztah přepíšeme pro účely klasifikace podle minimální vzdálenosti na
|
|
(2)
|
Cílem metody nejbližšího souseda je tedy nalezení subjektu (či objektu) z celé množiny všech subjektů , který má nejmenší vzdálenost od subjektu
, jenž chceme klasifikovat. Subjekt
poté přiřadíme do té třídy, ze které je nalezený nejbližší soused.
Metoda nejbližšího souseda je znázorněna na Obr. 1. Testovací subjekt bude zařazen do skupiny pacientů vzhledem k tomu, že jeho nejbližší soused je pacient.
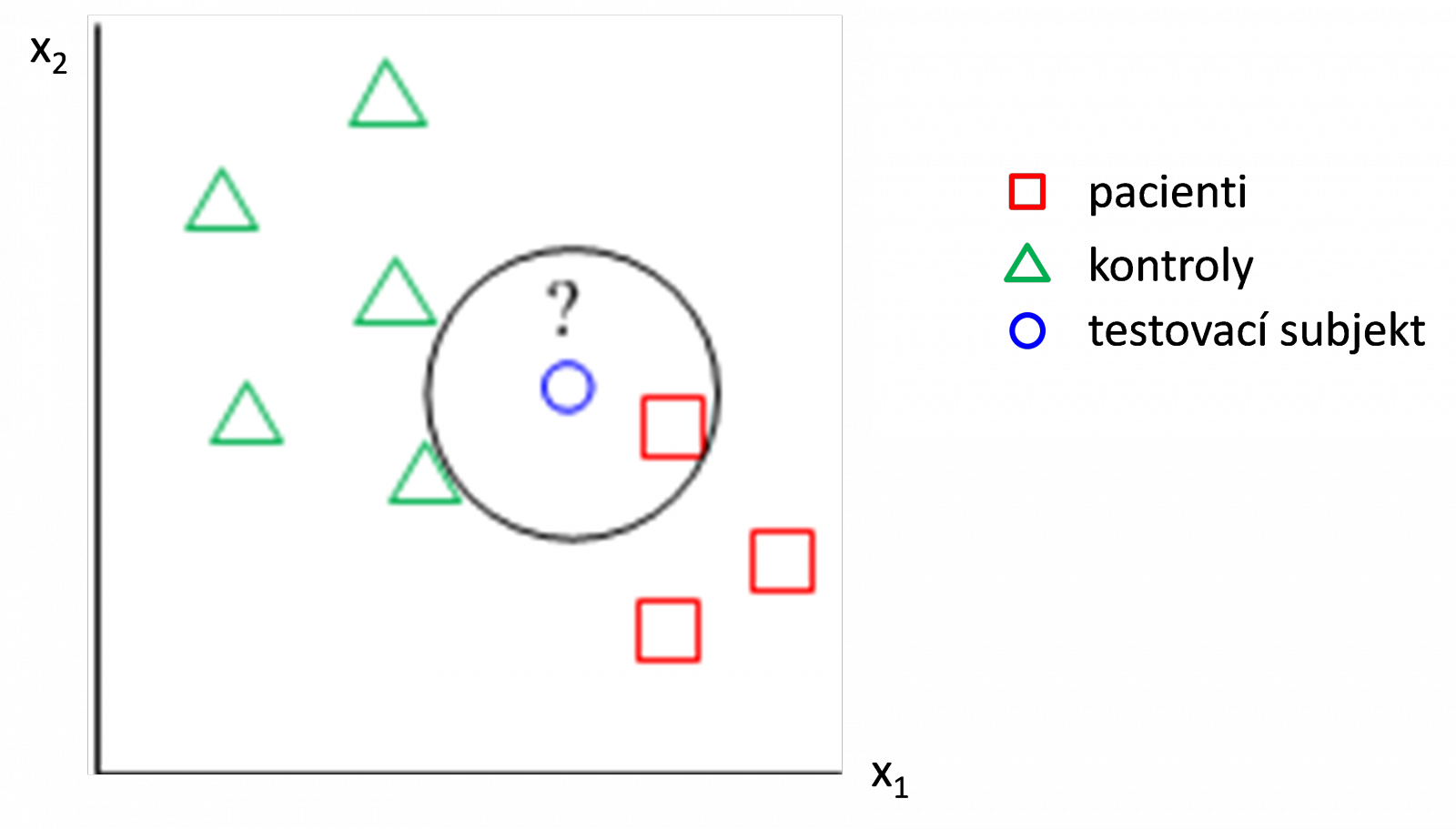
Nevýhodou metody nejbližšího souseda je její značná citlivost na odlehlé hodnoty. Obzvlášť v situaci, kdy se třídy částečně překrývají, zpravidla nedává dobré výsledky. Proto se v praxi častěji používá její zobecnění, což je metoda k nejbližších sousedů, při níž zařadíme subjekt, který chceme klasifikovat, do té třídy, která převažuje mezi jeho nejbližšími sousedy. Ukázka pro k=3 je uvedena na Obr. 2, kdy testovací subjekt zařadíme do třídy kontrol, protože mezi jeho třemi nejbližšími sousedy jsou dva kontrolní subjekty a pouze jeden pacient. Ze srovnání s Obr. 1. vyplývá, že metoda nejbližšího souseda a metoda k nejbližších sousedů mohou pro stejná data dávat různé výsledky.
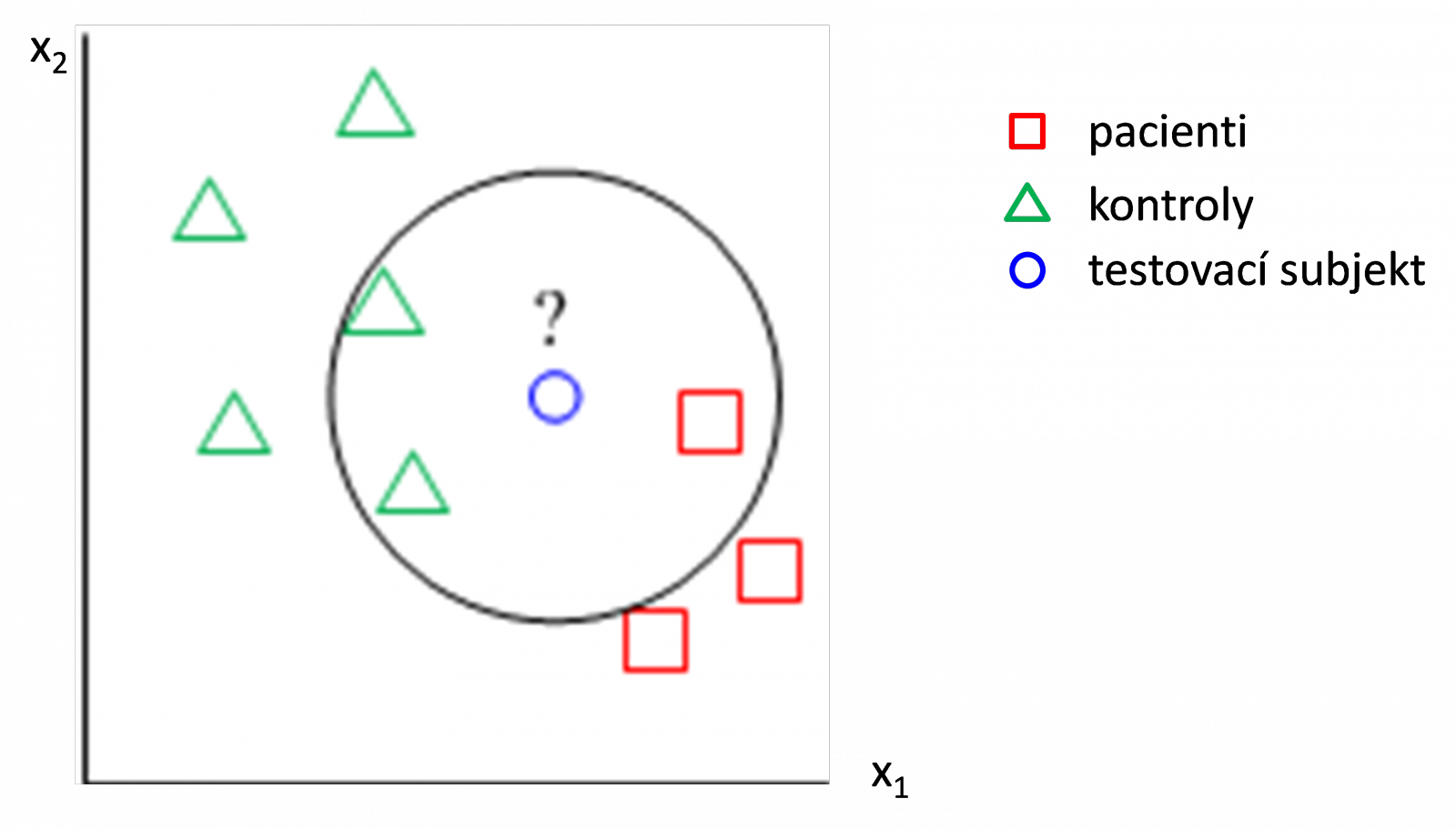
Obr. 2. Ilustrace klasifikace pomocí metody k nejbližších sousedů (zde konkrétně k=3). Testovací subjekt zatřídíme do skupiny kontrol, protože mezi jeho třemi nejbližšími sousedy převažují kontrolní subjekty.
U metody nejbližších sousedů zpravidla volíme za
liché číslo, protože pokud by
bylo sudé, mohlo by se stál, že by byl mezi
sousedy stejný počet subjektů z jedné i druhé skupiny, a tudíž by nebylo možné rozhodnout, do jaké třídy se má subjekt zařadit. Pokud by taková situace shody nastala, většinou se subjekt náhodně zařadí do jedné z daných skupin nebo případně do té skupiny, která je rizikovější. Protože bohužel dopředu nevíme, jaké
je nejvhodnější na naše konkrétní data, obvykle se klasifikace provádí za použití různých hodnot
a poté se vybere takové
, pro něž jsme dostali nejlepší výsledky. Abychom výběr
(tedy trénování klasifikátoru) neprováděli na stejném datovém souboru, na kterém klasifikátor i testujeme, protože to by to mohlo vést k přetrénování klasifikátoru, zpravidla se provádí výběr k pomocí křížové validace, jež je podrobně popsána v kapitole věnované hodnocení úspěšnosti klasifikace.
Metoda nejbližšího souseda ani metoda nejbližších sousedů nemají žádné předpoklady o rozložení dat (např. na rozdíl od Fisherovy lineární diskriminace ), což je jejich výhoda. Použití obou těchto metod však často není vhodné v situaci, kdy jsou značně nevyvážené počty subjektů v daných klasifikačních třídách. Protože pokud navíc dané třídy nejsou velmi od sebe vzdálené, budou obě metody zařazovat subjekty častěji do té třídy, která má větší počet subjektů.
