k-násobná křížová validace
Problém překryvu testovacích sad při testování externí validací s r opakováními řeší k-násobná křížová validace (označována rovněž jako k-násobná příčná validace, anglicky -fold cross-validation), při níž se datový soubor rozdělí na k částí, přičemž je vždy jedna část použita na testování a zbylých
částí je využito na trénování a postup se opakuje tak, že každá část je použita pro testování právě jednou (Obr. 2). Stejně jako u externí validace s
opakováními je výhodou poměrně přesný odhad klasifikační úspěšnosti a nevýhodou časová náročnost.
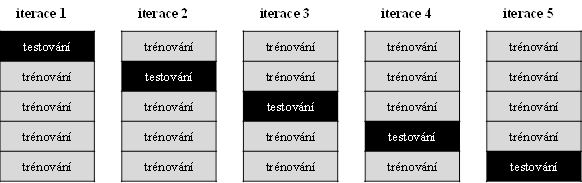
Obr. 2: Rozdělení datového souboru na trénovací a testovací sady při k-násobné křížové (zde k=5).
U -násobné křížové validace se za k nejčastěji volí 5 nebo 10 (tzn. rozdělení do 5 resp. 10 podsouborů). Speciálním případem je tzv. „odlož-jeden-mimo“ (leave-one-out nebo jackknife) křížová validace, kdy
, což znamená, že v každé z N iterací je jeden subjekt použit na testování a zbylých
subjektů na trénování. U této varianty křížové validace platí již zmíněné výhody i nevýhody, měli bychom mít však na paměti, že je časově nejnáročnější ze všech možných k. Výhodou je, že je velmi vhodná pro malé soubory dat a předností je i skutečnost, že na rozdíl od jakékoliv jiné k-násobné křížové validace dostaneme vždy pouze jeden výsledek úspěšnosti (tzn. výsledek úspěšnosti nezávisí na tom, jak se jednotlivé subjekty „namíchají“ do jednotlivých skupin). Pro velké datové soubory však „odlož-jeden-mimo“ křížová validace není doporučována, protože může lehce nadhodnocovat úspěšnost, proto se pro velké datové soubory doporučuje používat 10-násobnou křížovou validaci.
