Log-normální rozložení
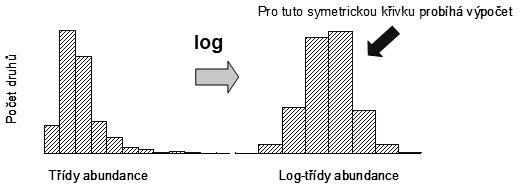
Mnoho studovaných společenstev organismů je log-normálně rozloženo, tento jev je v biologii poměrně obecný. Příkladem může být rozložení početnosti bílých krvinek v populaci. Předpokládá se, že toto rozložení se vyskytuje u velkých, pestrých a rozvinutých společenstev. Jedním z vysvětlení je, že jde o důsledek statistických vlastností velkých čísel a centrálního limitního teorému. Centrální limitní teorém říká, že při působení velkého množství faktorů na proměnnou způsobí náhodné variace těchto faktorů normální rozložení této proměnné; tento vliv se zesiluje při vzrůstajícím počtu faktorů. V našem případě jsou proměnnou abundance taxonů (logaritmicky standardizované) a faktory jsou všechny procesy působící v prostředí na společenstvo. Rozložení bylo poprvé použito Prestonem, který použil logaritmus o základu dvě pro standardizaci abundancí (vznikly tzv. oktávy – třídy abundance přestavující zdvojnásobení počtu jedinců (obr. 6.1)).
|
|
|
Obr. 6.1: Vztah log-normálního a normálního rozložení abundancí |
Rozložení je nejčastěji popisováno ve formě
|
|
(1) |
kde je inverzní šířka rozložení,
je počet druhů v
-té třídě v levé i pravé části symetrické křivky,
se označuje počet druhů v nejpočetnější třídě. Empirické studie ukázaly, že
je obvykle blízké 0,2.
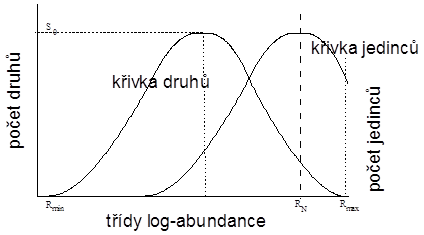
S log normálním rozložením je spjat také index diverzity , který je mírou vztahu mezi vrcholem křivky jedinců (modální oktáva křivky jedinců) a horní hranicí křivky druhů (oktáva s nejpočetnějšími druhy). Výpočet probíhá podle vztahu
|
|
(2) |
kde je označena nejpočetnější třída křivky jedinců a
třída křivky druhů obsahující nejpočetnější druhy (obr. 6.2). Jde vlastně o odhad počtu druhů v oktávě, kde křivka jedinců dosáhne vrcholu.
V mnoha případech leží vrchol křivky jedinců () ve stejném bodě jako horní hranice křivky druhů (
), potom
a hovoříme o takzvaném kanonickém log-normálním rozložení (kanonická hypotéza), kdy je směrodatná odchylka omezena jen na úzké rozpětí hodnot (
). Protože podobná situace nastává i u neekologických dat, je možné, že log-normální rozložení nemá žádné biologické pozadí, ale jde pouze o matematický artefakt. Na druhou stranu existuje řada příkladů společenstev, které lze vysvětlit kanonickou hypotézou. Sugihara také podává biologické vysvětlení kanonického log-normálního rozložení prostřednictvím modelu dělení niky, kde dělení niky přirovnává k rozbíjení kamene; velikost jeho úlomků bude také log-normálně rozložena, tato hypotéza tedy propojuje čistě stochastický model rozložení abundancí s na niku orientovanými modely. I když se uvádí, že korelace s empirickými daty nemusí být zárukou správnosti, jde o vhodnou pracovní hypotézu. Diskuse nad biologickým nebo matematickým původem log-normálního rozložení abundancí ovšem neustávají. Podle Uglanda budou druhově bohatá společenstva (s více než 50 druhy) nejspíše vždy kanonická, neboť
je jejich matematickou vlastností. Také v případě
se zdá, že jde o matematický artefakt velkého počtu druhů.
|
|
|
Obr. 6.2: Vztah křivky druhů a křivky jedinců u log normálního rozložení abundancí (index diverzity |
S výpočtem log-normálního rozložení abundancí se váže ještě další problém, a to nezachycení velmi vzácných druhů (levá strana křivky). Výsledkem je takzvaná zkrácená log-normal křivka, její výpočet popsal Pielou.
Alternativní metodou pro proložení log-normálního rozložení daty abundancí je metoda popsaná, takzvaná Poissonova log-normální metoda, která předpokládá, že spojitá log-normální křivka je reprezentována řadou nespojitých tříd abundance, které se chovají jako složené Poissonovské proměnné.
Společenstva popsaná log-normálním rozložením lze často úspěšně proložit také rozložením logaritmické řady nebo i jinými modely. Také by mohlo k jejich vzniku dojít díky špatné identifikaci druhů nebo chybou vzorkování. Podle některých autorů by log-normální rozložení nemělo být používáno pro data abundancí. I přesto je zde mnoho příkladů vzorkování, které lze úspěšně popsat log-normálním rozložením. Zdá se, že log-normální rozložení zůstane i nadále významným nástrojem při studiu diverzity.
