Základní schémata statistické analýzy dat
V předcházejících kapitolách jsme si ukázali jak z mikročipových experimentů pomocí analýzy obrazu a následných úprav (filtrace, normalizace, sumarizace) vzniká finální N x p datová matice, která obsahuje informaci o expresi (aktivitě) p genů u N vzorků experimentu. Těmto datům se také říká "normalizovaná", anglicky "normalized".
Jak vidíte, proces vzniku této matice dat je komplexní a je velmi důležité rozumět každému kroku, protože nesprávný způsob zpracování může mít velice negativní vliv na výsledky. Jako analytici byste se proto nikdy neměli spokojit s daty, které upravil a normalizoval do finální matice někdo jiný bez toho, aby jste měli všechny důležité informace o tom, jak tento proces proběhl (nejlépe i kód). Úplně nejlepší je požádat o data základní a upravit si je podle vlastního uvážení.
Tato finální matice genomických/proteomických dat se pak obvykle kombinuje s maticí údajů o vzorcích (např. klinické informace o pacientech,jejichž vzorky byly hybridizovány na mikročipu) nebo maticí ůdajů o genech (který gen patří na který chromozom, jaká je jeho pozice na genu, jeho funkce...) v následné (nejenom) statistické analýze dat.
Každý experiment má odlišné hypotézy a tedy i odlišnou analýzu dat, která vede k jejich potvrzení nebo vyvrácení, avšak existují tradiční schémata, která se opakují. Obrázek níže tyto schémata popisuje od biologické otázky až k publikaci. Červené šipky naznačují důležitost přitomnosti analytika dat ve dvou základních krocích přípravy dat: dizajnu experimentu a již vzpomenuté úpravy a normalizaci dat.
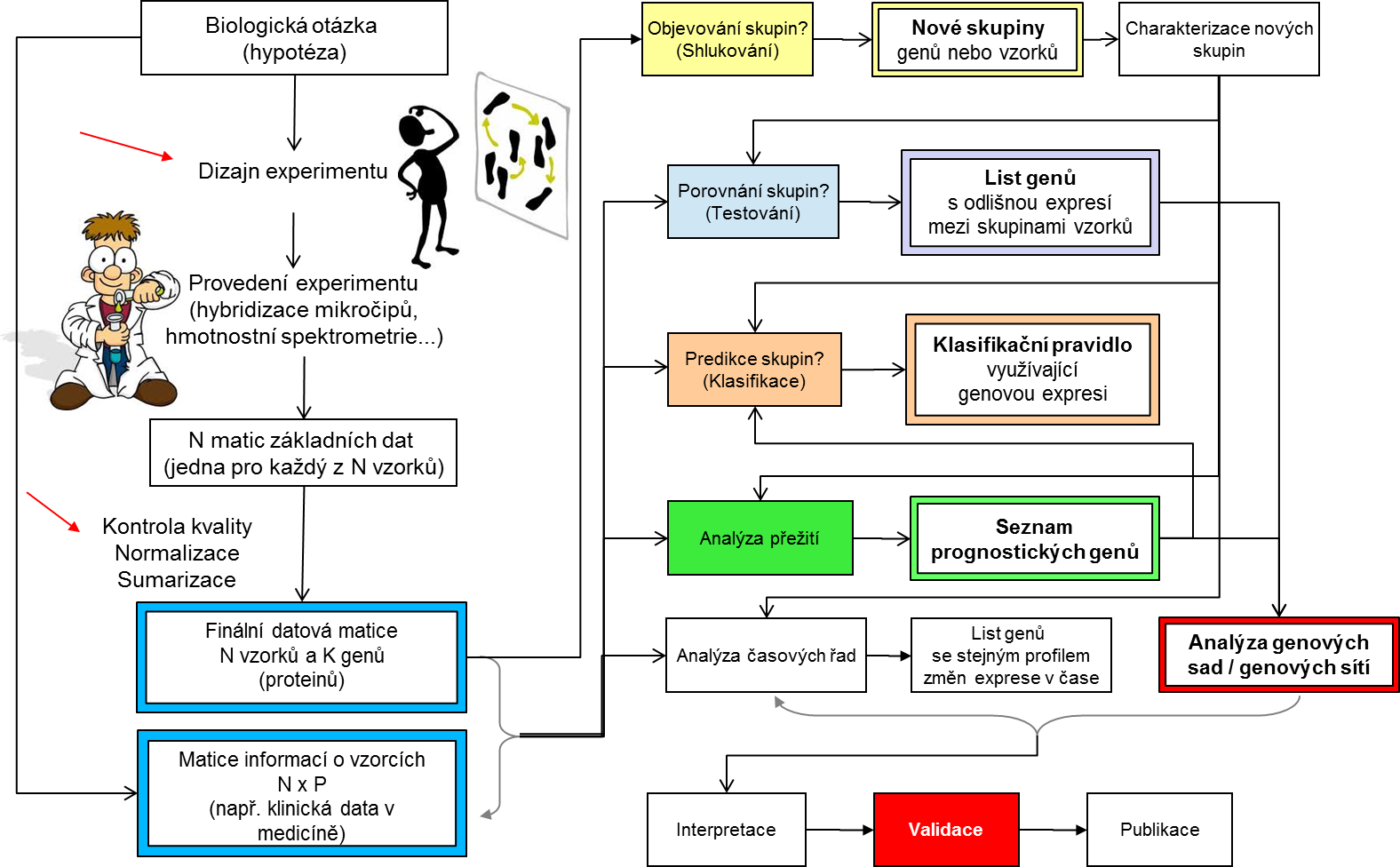
Obecně můžeme statistickou analýzu dat, která má odpovědět na biologické hypotézy, rozdělit na čtyři hlavní (i když ne vyčerpávající) druhy analýzy - každá z nich odpovídá na jinou hypotézu a využívá jiné metody analýzy. Je velice důležité, abyste jako analytici byli schopni z položených biologických otázek správně identifikovat druh analýzy, protože ta určuje jaké metody máte použít, ale také přímo ovlivňuje dizajn experimentu, u kterého by jste jako analytici rozhodně měli být a proto mu také budeme věnovat samostatnou podkapitolu.
Tradiční schémata statistické analýzy dat by se dali rozdělit následovně:
- Učení s učitelem (angl. supervised learning) - v tomto případe zobecňujeme známou strukturu dat na data nové. Sem patří:
- Porovnávaní skupin (class comparison) - zde například hledáme rozdíly v expresi, počtě kopií genů nebo abundanci proteinů mez již definovanými skupinami
- Predikce skupin (class prediction) - na známých skupinách se snažíme vytvořit rozhodovací pravidlo (klasifikátor), který by dokázal zařadit novou vzorku do jedné ze skupin
- Učení bez učitele (angl. unsupervised learning) - v tomto případě struktura v datech není známa a musíme ji objevit. Sem patří:
- Objevování skupin (class discovery) - na základě informací o genech a proteínech hledáme nové skupiny
