Základy regulárních výrazů
Na regulární výraz se můžeme dívat jako na rozšíření operátoru LIKE. Jde o textovou šablonu, která se skládá z:
- hledaných znaků
- zástupných znaků
- kvantifikátorů
- operátorů
- modifikátorů
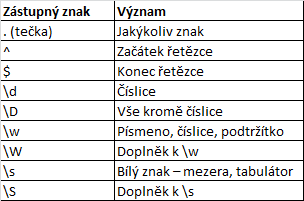
Zatímco operátor LIKE má pouze 2 zástupné znaky, u regulárních výrazů je nabídka širší. Zástupným znakem můžeme odlišit např. číslici od písmena nebo tzv. bílého znaku (mezera, tabulátor). Přehled základních zástupných znaků uvádí Tabulka 12.
Tabulka 12: Zástupné znaky v regulárních výrazech
 |
Pokud potřebujeme v textu hledat samotný zástupný znak v původním významu, tedy například tečku, musíme před hledaný znak umístit zpětné lomítko. Toto pravidlo platí pro všechny speciální znaky regulárních výrazů.

Uvedeným výrazem hledáme tříznakové řetězce, které začínají "^." a libovolným následujícím znakem.
Zástupný znak zastupuje vždy právě jeden znak v prohledávaném řetězci. Toto chování můžeme změnit pomocí tzv. kvantifikátorů, které v regulárním výrazu umístíme těsně za daný zástupný znak. Přehled kvantifikátorů je uveden v Tabulce 13.
Tabulka 13: Kvantifikátory v regulárních výrazech
|
Kvantifikátor |
Význam |
|
* |
0 – n opakování ("greedy" chování) |
|
*? |
0 – n opakování ("nongreedy" chování) |
|
+ |
1 – n opakování ("greedy" chování) |
|
+? |
1 – n opakování ("nongreedy" chování) |
|
? |
0 nebo 1 opakování |
|
{m} |
Přesně m opakování |
|
{m,} |
m nebo více opakování |
|
{m,n} |
Minimálně m, maximálně n opakování |
Spojením zástupného znaku "." a kvantifikátoru " * " dostáváme regulární výraz, který pokrývá libovolný textový řetezec. Tuto kombinaci používáme ve dvou variantách:
- "hladová" (greedy)
- "nehladová" (nongreedy)
Pokud použijeme hladovou variantu, bude se hledat shoda s co nejdelším řetězcem, naopak nehladová varianta hledá shodu s co nejkratším řetězcem. Blíže se na tento problém podíváme v další části kapitoly věnované nahrazování podřetězců s použitím regulárních výrazů.
Pokud bychom hledali v textu datum, mohli bychom použít tento regulární výraz:

Hledáme jednu až dvě číslice jako den, následuje tečka, jedna až dvě číslice na pozici měsíce, tečka a dvě až čtyři číslice na pozici roku. Pokud by komponenty datumu oddělovaly kromě tečky i mezery, rozšířili bychom výraz o mezeru s otazníkem za každou tečku:
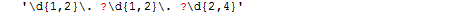
Ani tento výraz však není stále ideální, protože den i měsíc může ve skutečnosti na první pozici obsahovat jen vybrané číslice, konkrétně den 0, 1, 2 nebo 3, měsíc pouze 0 nebo 1. Tento problém nám pomohou řešit tzv. operátory regulárních výrazů. Jejich přehled je uveden v tabulce 14.
Tabulka 14: Operátory regulárních výrazů
|
Operátor |
Význam |
|
| |
nebo |
|
[abc] |
Jeden z uvedených znaků (a nebo b nebo c) |
|
[^abc] |
Libovolný znak kromě uvedených (vše kromě a b c) |
|
(abc) |
Uzavření skupiny znaků - blok |
|
1, 2, 3, ... |
Odkaz na první, druhý, třetí blok |
Pro specifikaci vybraných znaků můžeme využít buď operátor svislítko "|" nebo operátor hranatých zvorek. Upravený výraz pro hledání datumu může vypadat takto:

V tomto případě jsou obě varianty rovnocenné, rozdíl by byl, pokud bychom kombinovali operátor se zástupným znakem. Zatímco operátor svislítko zástupné znaky interpretuje, operátor hranatých závorek nikoliv. Výraz hledající v textu číslici nebo bílý znak proto musí vypadat takto:
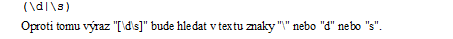
Pomocí kulatých závorek můžeme vybranou skupinu znaků uzavřít do bloku a na ten se pak následně odkazovat pomocí zpětného lomítka a čísla pořadí bloku. Tuto techniku použijeme, pokud hledáme například repetitivní vzor a chceme ho definovat co nejobecněji. Například pokud hledáme opakování tří stejných číslic, můžeme napsat:

Říkáme tím, že chceme najít číslici 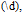 , za kterou se má opakovat stejný znak
, za kterou se má opakovat stejný znak 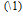 . Výraz je podstatně kratší než rovnocenný výraz s použitím operátoru svislítka a výpisem všech variant:
. Výraz je podstatně kratší než rovnocenný výraz s použitím operátoru svislítka a výpisem všech variant:
'(111|222|333|444|555|666|777|888|999|000)'
Pomocí odkazů můžeme hledat text, který začíná dvěmi nečíselnými znaky a končí stejnými znaky v opačném pořadí:

Poslední komponentou regulárních výrazů jsou modifikátory, které mění chování celého procesu vyhledávání. Základním modifikátorem je volba, zda chceme při vyhledávání rozlišovat velikost písmen. Pokud ano, jde o "case sensitive" hledání, pro které se používá znak "c", pokud ne, jde o "case insensitive" označované znakem "i".
