Použití regulárních výrazů v databázi POSTGRESQL
V databázi POSTGRESQL najdeme místo funkce REGEXP_LIKE() operátor "~" (vlnka), který provádí porovnání řetězce s regulárním výrazem s ohledem na velikost písmen (case sensitive), zatímco operátor "~*" porovnává shodu bez ohledu na velikost písmen (case insesitive).
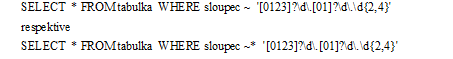
Funkce REGEXP_SUBSTR() je v POSTGRESQL zastoupena funkcí SUBSTRING(), jejíž syntaxe je následující:
SUBSTRING(text, reg.vyraz)
Extrakci datumu z textového sloupce bychom tedy v databázi POSGRESQL provedli takto:
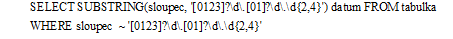
Oproti funkci REGEXP_SUBSTR() je tu užitečná výhoda, že můžeme ze specifikovaného regulárního výrazu extrahovat pouze omezenou část, kterou uzavřeme do kulatých závorek. Zatímco tedy předchozí příklad vrátí celé datum, v následujícím příkladu můžeme drobným doplněním regulárního výrazu získat pouze rok z nalezeného datumu:
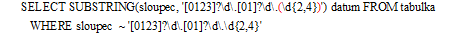
Shodný název jak v databázi ORACLE tak POSTGRESQL mají funkce pro nahrazení nalezeného podřetězce za jiný text. Jde o funkci REGEXP_REPLACE(), kde rozdíl je pouze ve volitelných parametrech. Syntaxe v POSTGRESQL je:
REGEXP_REPLACE (text, reg.vyraz, novy_text [, priznaky ])
V prohledávaném textu je nahrazen nalezený vzor za nový text. Pomocí příznaků ovlivňujeme chování funkce. Nejdůležitější příznaky shrnuje tabulka 15:
Tab. 15: Přehled nejvýznamnějších příznaků funkce REGEXP_REPLACE v POSTGRESQL
|
Příznak |
Význam |
|
g |
Nahradit všechny výskyty regulárního výrazu |
|
i |
Porovnávání bez ohledu na velikost písmen |
|
c |
Porovnávání s ohledem na velikost písmen |
Pokud chceme v textu zamaskovat čísla hvězdičkou, můžeme použít toto řešení:
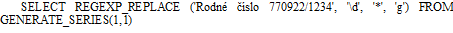
Příznak "g" zajistí, že budou zaměněny všechny nalezené číslice.
