Databázové vyhledávání
Po zpracování základních dat (přepočet profilových spekter na čárové a rekalibraci) můžeme přejít k hlavnímu kroku vyhodnocovaní LC-MS/MS dat a sice databázovému vyhledávání. V tomto kroku se naměřené spektra porovnávají s teoretickými spektry odvozenými od známých proteinových sekvencí a získáme tak seznam identifikovaných peptidů, ze kterých pak "seskládáme" proteiny.
Začíname vždy přípravou dat, ve které vybíráme reprezentatívní kvalitní spektra, nebo naopak odstraňujeme ty méně kvalitní. Jednoduchou metodou je výber několika (N) nejlepších (nejsilnějších) signálů z okna o zvolené šířce. Příkladem komplikovanějšího postupu je dekonvoluce signálu a šumu, kdy ve spektrach omezíme přítomnost šumu.
Dále si musíme připravit databázi, proti které budeme prohledávat. Typicky jde o strojový překlad sekvence genů ve všech šesti čtecích rámcích a výběr nejdelšího překladu. Překlady se pak dle zadaných použitých enzymů naštěpí na peptidy.
Ve vlastním prohledávání se ke každému spektru přiřadí jeden nebo více peptidů. Využívají se zde různé skórovácí funkce, prahování (skóre musí byt větší než předem stanovená hodnota) a další nástroje pro kontrolu falešně pozitivních výsledků (decoy databáze, FDR, percolator). Decoy databáze vzniká v zásadě dvěma způsoby: (i)převrácením peptidových sekvencí (od konce k začátku), nebo (ii) vytvořením náhodných sekvencí o podobných parameterch (délka, rozdělení aminokyselin a pod.). Decoy databáze tak představuje náhodou falešnou databázi a slouží ke kontrole FDR (false discovery rate). Shody s decoy databází považujeme za falešně pozitivní a minimální hodnotu skóre peptidů proti původné databázi zvolíme tak, abychom minimalizovali počet falešne pozitivních identifikací.
Dalším nástrojem je Percolator, který ilustruje obrázek níže:
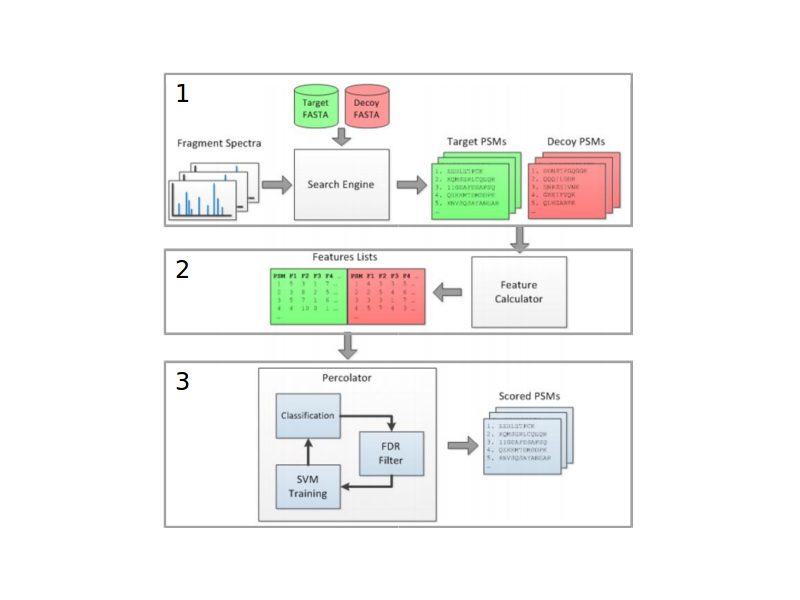
Prvním krokem je prohledání dat proti původní i decoy databázi a výpočet vlastností peptidů (skóre, chyba hmotnosti, intensita, přítomnost modifikací a dalši fyzikálně-chemické vlastnosti). S pomocí metody SVM (Support vecto machines), která vytváří klasifikátor peptidů na pozitivní (shoda s původní databází) a falošně pozitivní (shoda s decoy databází). Klasifikátor nastavuje váhy konkrétních vlastností. Konečné skóre peptidů je pak výsledkem přepočtu původních hodnot s využítím vah ze SVM. Dle našich zkušeností dostávame po použití Percolatora více identifikovaných peptidů.
