Část 2: Skupiny plodin na základě nutričních hodnot
Do kolika skupin bychom mohli rozdělit plodiny na základě nutričního složení jejich produktů (obsah cukrů, tuků, proteinů a vlákniny)?
Tento problém vyřešíme pomocí analýzy hlavních komponent - PCA.
Existují dvě funkce pro PCA:
- princomp() – R-mode PCA, vlastní čísla, více pozorování než parametrů
- prcomp() – Q-mode PCA, singulární rozklad
Informace o nutričním složení se nachází v souboru plodiny, ve sloupcích 6 až 9. Aplikujeme funkci prcomp(), nejdříve ale přejmenujeme názvy řádku podle jména plodin, aby se nám v grafu pěkně zobrazily:
> rownames(plodiny)<-plodiny[,1]
> pr1<-prcomp(plodiny[,6:9])
Funkce biplot() vykreslí plodiny v prvních dvou komponentech a zároveň efekt, jaký mají jednotlivé nutriční proměnné na rozdělení plodin:
> biplot(pr1)
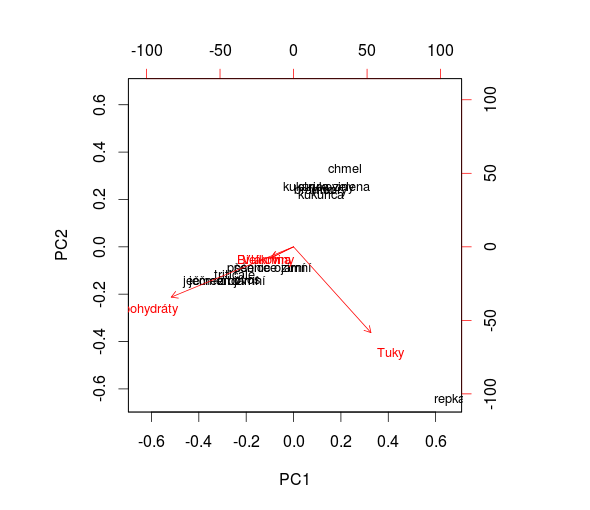
Jednoznačně vidíme, že například řepka olejná je odlehlá hodnota a vliv na to má její velký obsah olejů (proměnná tuky). Ječmen, pšenice, žito, oves a triticale tvoří samostatnou skupinu s vysokým podílem karbohydrátů.
Dle výsledků PCA tedy můžeme říct, že plodiny se dělí na tři hlavní skupiny.
