Genetické vzdálenosti
Genetické vzdálenosti počítáme vždy z alignovaných sekvencí (Alignment). Nejjednodušší genetická vzdálenost představuje počet rozdílů v nukleotidových bázích mezi dvěma sekvencemi. Pokud je tento počet vztáhnutý k délce celého alignmentu, jedná se o nekorigovanou -vzdálenost (uncorrected
-distance).
Výjimka: Genetické vzdálenosti lze počítat i na mezigenomové úrovni. Při porovnávání genomů ale alignment představuje zásadní problém hlavně u vzdáleně příbuzných organismů kvůli genomovým přestavbám. Genetické vzdálenosti nezávislé na alignmentu se pak počítají z výskytu krátkých oligonukleotidů, nejdelších shodných sekvencí, nebo pomocí metod informační teorie.
Nekorigovaná -vzdálenost mezi sekvencemi 1 a 2a na obr. 3 je 1/14 = 0.07, ale mezi sekvencemi 1 a 2b je 0/14 = 0. Pokud ale platí vztah mezi sekvencemi zobrazený vpravo, genetická vzdálenost mezi sekvencemi 1 a 2b je podhodnocena, protože se v úseku v porovnání s nejbližším společným předkem došlo ke dvěma mutacím. Pozice, kde se vyskytuje stejná nukleotidová báze, ale na daném místě se objevila po vícenásobných mutacích, se nazývá saturována. U dlouhodobých divergencí se saturace pozic dá očekávat relativně běžně, jelikož sekvenci DNA tvoří jenom čtyři nukleotidové báze.
Otázka: Pokud jsou tranzice častější než transverze, co z toho vyplývá pro modelování vícenásobných mutací v sekvenci DNA?
Je pravděpodobnější, že pokud se v dané pozici vyskytly vícenásobné mutace, častěji se bude jednat o tranzice, čili substituce mezi adeninem a guaninem a mezi cytozinem a tyminem.
Určení genetické vzdálenosti proto potřebuje korekci pro vícenásobné mutace a saturaci pozic, abychom se přiblížili ke skutečné hodnotě. Takovou korekci poskytuje substituční model.
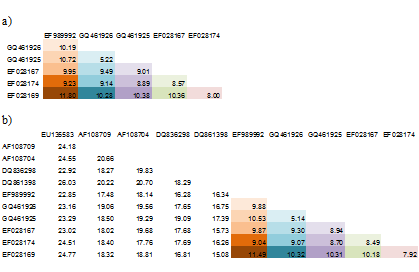
Korigované genetické vzdálenosti představují reálnější hodnotu než nekorigované, ale zároveň použití parametrizovaného substitučního modelu znemožňuje přímé porovnání s jinými studiemi (Tab. 1). Korigované vzdálenosti proto používáme pro následné výpočty a pro demonstraci základní divergence mezi taxony uvádíme nekorigované vzdálenosti.
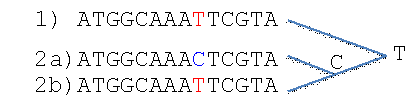
Obr.3: Při porovnaní sekvencí 1 a 2a pozorujeme jednu substituci, ale mezi sekvencemi 1 a 2b není na vybraném úseku rozdíl. Pokud ale pro uvedený příklad platí vztahy naznačené vpravo, dovedeme pomocí substitučního modelu odhadnout, že mezi sekvencemi 1 a 2b došlo ke zpětné mutaci, jak je zobrazeno na kladogramu.
Tab.1: Vliv parametrů substitučního modelu na určování genetických vzdáleností. Genetické vzdálenosti (%) byly vypočítány pomocí Kimura-dvouparametrového (K2P) modelu, kde poměr rychlostí tranzicí a transverzí (κ) byl určen z dat. a) Pro zájmovou skupinu šesti sekvencí je κ = 7.95. b) Pokud se k těmto sekvencím přidají další údaje, κ = 2.33 a korigované genetické vzdálenosti se mění i u zájmové skupiny.