Cíl biostatistiky a základní pojmy
Hlavním cílem biostatistiky je získání informace o tzv. cílové populaci (target population), jejíž prvky jsou nejčastěji dány vymezením společných vlastností. Příkladem může být populace pacientek s karcinomem prsu či populace mužů starších 60 let. Na druhou stranu, prvky cílové populace mohou být dány i výčtem, můžeme např. studovat populaci zdravotnických zařízení v ČR nebo populaci studentů Lékařské fakulty Masarykovy univerzity. Ve většině případů je však zjišťování sledovaných charakteristik u všech subjektů cílové populace nereálné a my jsme v našem bádání omezeni pouze na část cílové populace, tzv. výběr z cílové populace neboli experimentální vzorek (experimental sample).
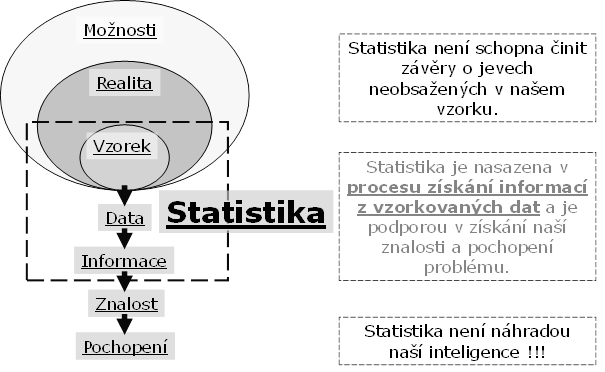
Experimentální vzorek představuje podsoubor cílové populace zahrnutý v naší studii nebo experimentu. Jinak řečeno, je to skupina subjektů, kterou máme k dispozici a která představuje pozorování (observations) cílové populace. Sledované vlastnosti experimentálního vzorku pro hodnocení převedeme na číselné vyjádření neboli data (observed data). Ta jsou dále předmětem našeho zájmu, nicméně to, jak budeme dále postupovat při jejich hodnocení, do značné míry závisí na účelu studie nebo experimentu. Obecně se dá říci, že předpokládáme určité pravděpodobnostní chování neboli model (probabilistic model) studované cílové populace a tím i experimentálního vzorku. Konkrétní problém následně vyjádříme v našem modelu jako hypotézu, jejíž platnost vyhodnotíme na základě vybraného modelu a pozorovaných dat (obrázek 1).
|
Obr. 1: Pozice statistické analýzy dat v procesu pochopení biologických a medicínských jevů. |
Charakteristika sledovaná u cílové populace se nejčastěji označuje jako znak (characteristic, feature). Jinak řečeno, znaky odpovídají sledovaným vlastnostem subjektů cílové populace. Dle povahy popisu jednotlivých variant daného znaku dělíme znaky na kvalitativní (qualitative) a kvantitativní (quantitative). Můžeme-li jednotlivé varianty vyjádřit slovně, mluvíme o znaku kvalitativním. Naopak, můžeme-li varianty vyjádřit číslem, mluvíme o znaku kvantitativním. Slovní vyjádření jsou pro jakékoliv matematické zpracování nevhodná, proto i varianty kvalitativního znaku převádíme na čísla (na rozdíl od kvantitativních znaků jsou však tato čísla pouze pomocná a nemají většinou žádnou interpretaci). Rozdělení typů znaků je klíčovým prvkem v každé analýze dat a determinuje metody, které je možné na data nasadit. Číselnou reprezentaci daného znaku, která je nezbytná pro statistické zpracování, pak nazýváme veličinou (variable). Vzhledem k tomu, že ve statistice a tudíž i v biostatistice reprezentujeme skutečnost matematickým modelem, ve kterém hraje roli náhoda, představuje měření daného znaku u jednoho prvku experimentálního vzorku výsledek náhodného pokusu. V tomto případě nazýváme číselnou reprezentaci daného znaku náhodnou veličinou (random variable). Konkrétní číselný výsledek náhodného pokusu, tedy pozorovanou hodnotu náhodné veličiny u -tého prvku experimentálního vzorku, pak označujeme jako realizaci náhodné veličiny (realization of a random variable). Náhodná veličina má v biostatistice klíčové postavení, neboť je základním konceptem všech biostatistických úloh, v detailu se náhodné veličině věnuje kapitola Bodové a intervalové odhady.
