Konstrukce intervalů spolehlivosti pro parametry normálního rozdělení
V této části kapitoly odvodíme intervaly spolehlivosti jak pro oba parametry normálního rozdělení, a
.
Konstrukce 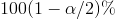 intervalu spolehlivosti pro parametr
intervalu spolehlivosti pro parametr 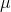
Mějme náhodný výběr z normálního rozdělení pravděpodobnosti, tedy předpokládejme, že platí
. Nejprve budeme uvažovat situaci, kdy hodnotu
známe. Úpravou vztahu (17) pak dostáváme:
|
. |
(6) |
Vidíme, že jsme s pomocí pravděpodobnosti a známých kvantit vypočítali dolní a horní mez, které zdola a shora omezují neznámý parametr . Správně bychom řekli, že
interval spolehlivosti představuje oblast, která s pravděpodobností
pokrývá neznámý parametr
.
interval spolehlivosti pro parametr
má tedy tvar
|
|
(7) |
Výraz jsme již dříve definovali jako standardní chybu výběrového průměru (viz vzorec (4)), proto
interval spolehlivosti pro parametr
můžeme ještě vyjádřit v alternativní formě jako
|
|
(8) |
Výše uvedené jsme odvozovali za předpokladu, že známe přesnou hodnotu parametru , což je však z praktického hlediska značně omezující (reálným příkladem však může být intervalový odhad střední hodnoty pro data měřená přístrojem s kalibrovanou a tudíž známou přesností). Ve chvíli, kdy neznáme hodnotu parametru
, musíme pro konstrukci intervalu spolehlivosti použít jinou statistiku než
, s jiným rozdělením pravděpodobnosti. Logické by bylo místo směrodatné odchylky,
, použít výběrovou směrodatnou odchylku,
, nicméně tato náhrada není úplně jednoduchá, nejedná se o pouhé dosazení
za
. Pomůžeme si vztahem, který definuje statistiku se Studentovým
rozdělením. Statistika
vypadá stejně jako statistika
, jen namísto směrodatné odchylky,
, obsahuje výběrovou směrodatnou odchylku,
. To je přesně to, čeho jsme chtěli dosáhnout. Je však důležité si uvědomit, že statistika
má jiné rozdělení pravděpodobnosti než
, tedy i jinou kvantilovou funkci. Stejnými úpravami jako v případě intervalu spolehlivosti pro parametr
při známém
dostaneme
interval spolehlivosti pro parametr
při neznámém
ve tvaru:
|
|
(9) |
kde a
jsou
, respektive
, kvantily Studentova
rozdělení s
stupni volnosti.
Příklad 2. Chceme sestrojit 95% interval spolehlivosti pro střední hodnotu systolického tlaku studentů vysokých škol. Na vzorku =100 náhodně vybraných studentů byl výběrový průměr systolického tlaku roven hodnotě 123,4 mm Hg s výběrovou směrodatnou odchylkou
= 14,0 mm Hg. Kromě těchto hodnot je třeba k výpočtu 95% intervalu spolehlivosti ještě hodnota kvantilu
rozdělení příslušného hladině
= 0,05 a
= 99 stupňům volnosti. V tabulkách nebo příslušném software najdeme, že
(99)=1,98. Dosazením do vzorce (9) získáme
|
|
(10) |
což znamená, že 95% intervalem spolehlivosti pro střední hodnotu systolického tlaku studentů vysokých škol je interval (120,6 mm Hg; 126,2 mm Hg). Můžeme tedy říci, že s pravděpodobností 95 % interval (120,6 mm Hg; 126,2 mm Hg) pokrývá neznámou střední hodnotu systolického tlaku studentů vysokých škol.
Konstrukce intervalu spolehlivosti pro parametr 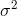
Opět předpokládejme náhodný výběr z normálního rozdělení pravděpodobnosti, tedy
. Pro konstrukci
intervalu spolehlivosti pro parametr
použijeme vzorec využívající chí-kvadrát rozdělení, kde
je
procentní kvantil chí-kvadrát rozdělení s
stupni volnosti:
|
. |
(11) |
interval spolehlivosti pro parametr
má tedy tvar
|
|
(12) |
