Standardizované normální rozdělení
Mezi výhodné vlastnosti normálního rozdělení patří zachování normality při změně měřítka osy, na které měříme jednotky náhodné veličiny . Jinými slovy, pokud veličinu
s rozdělením
transformujeme podle vztahu
, pak platí, že náhodná veličina
má rozdělení pravděpodobnosti
. S využitím této vlastnosti jsme vždy schopni transformovat náhodnou veličinu
s rozdělením
na náhodnou veličinu
s rozdělením
, tedy s normálním rozdělením s nulovou střední hodnotou a jednotkovým rozptylem. Platí
|
|
(12) |
Toto rozdělení má ve statistice výsadní postavení a označuje se jako standardizované normální rozdělení (standard normal distribution). Výhoda je, že všechny hodnoty distribuční i kvantilové funkce jsou tabelovány a obsaženy v dostupných softwarech (kvantily standardizovaného normálního rozdělení se označují jako ). Můžeme tak jednoduše kvantifikovat pravděpodobnost, s jakou se náhodná veličina Z se standardizovaným normálním rozdělením realizuje nad určitou hodnotou z (případně pod ní, nebo mezi dvěma danými hodnotami). Obecně lze plochu pod hustotou rozdělit pomocí kvantilu na dvě části, např. pomocí
procentního kvantilu, označme ho
, na část s plochou
a na část s plochou
(viz obrázek 3.2). Toto dělení samozřejmě odpovídá pravděpodobnosti, tedy náhodná veličina
se realizuje číslem menším než
s pravděpodobností
a číslem větším než
s pravděpodobností
.
Transformace na standardizované normální rozdělení (tzv. -skore) má také přímé praktické využití, v medicíně se používá například při diagnostice osteoporózy, kdy je
-skore počítáno pro výsledky denzitometrického vyšetření pacienta vzhledem k průměru a směrodatné odchylce referenční populace.
Příklad 2. Při populačním epidemiologickém průzkumu se zjistilo, že průměrný objem prostaty u mužů (veličina ) je 52,73 ml se směrodatnou odchylkou rovnou 13,12 ml. Předpokládáme, že objem prostaty se řídí normálním rozdělením, za hodnoty parametrů
a
bereme populační odhady. Zajímá nás, jaká je pravděpodobnost, že objem prostaty u muže bude větší než 80 ml. Abychom zjistili, jaká pravděpodobnost přísluší hodnotě 80 ml jako kvantilu rozdělení náhodné veličiny
, provedeme standardizaci a zjistíme příslušnou pravděpodobnost na základě kvantilu standardizované normální veličiny
. Výpočet hodnoty veličiny
je následující:
|
|
(14) |
Víme, že hodnota 2,08 představuje procentní kvantil,
, standardizované normální veličiny
, k ní odpovídající hladinu
zjistíme z tabulek hodnot kvantilové funkce. Lze zjistit, že pravděpodobnost výskytu hodnoty větší než 2,08 je pro standardizovanou normální veličinu rovna 0,0188, což tedy znamená, že pravděpodobnost výskytu prostaty s objemem větším než 80 ml je rovna přibližně 2%.
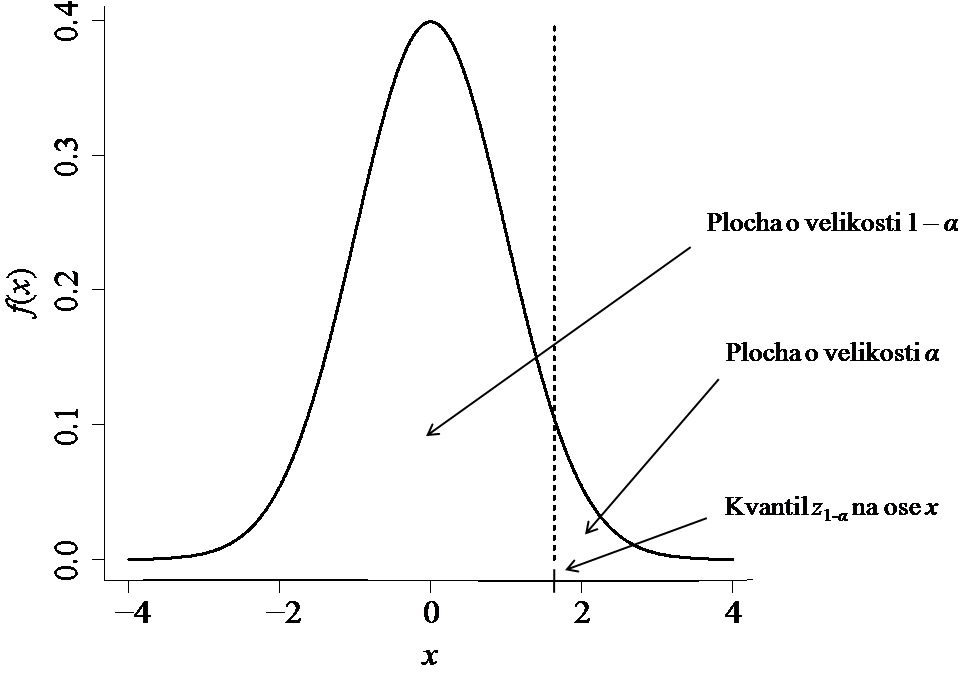 |
Obr. 3.3: Plochy pod hustotou pravděpodobnosti příslušné kvantilu .
Oblast, kde se náhodná veličina se standardizovaným normálním rozdělením realizuje s pravděpodobností lze vyjádřit pomocí její distribuční funkce (ta vyjadřuje pravděpodobnost, že číselná realizace náhodné veličiny nepřekročí na reálné ose danou hodnotu) a příslušných kvantilů. Jinými slovy, oblast realizace náhodné veličiny
s rozdělením
odpovídající pravděpodobnosti
lze vymezit pomocí jejích kvantilů.
Klíčové kvantily standardizovaného normálního rozdělení uvádí obrázek 3.4, ze kterého vyplývá, že náhodná veličina s rozdělením se s pravděpodobností 90% realizuje mezi hodnotou -1,64 a hodnotou 1,64, s pravděpodobností 95% mezi hodnotami -1,96 a 1,96 a s pravděpodobností 99% nepřekročí v absolutní hodnotě číslo 2,58.
 |
Obr. 3.4: Klíčové kvantily standardizovaného normálního rozdělení pravděpodobnosti.
Vymezení oblasti, kde se náhodná veličina realizuje s určitou pravděpodobností je platné pro všechna rozdělení pravděpodobnosti, nejen pro standardizované normální (i když u rozdělení se vzhledem k jeho symetrii významné kvantily dobře pamatují). Tento fakt je velmi důležitý zejména v testování hypotéz, kde na základě toho, v jaké oblasti se realizuje hodnota testové statistiky (náhodné veličiny s daným rozdělením pravděpodobnosti), rozhodujeme o platnosti nebo neplatnosti sledované hypotézy.
