Řešený praktický příklad: Spotřeba automobilů
Nejprve si do programu R načteme datový soubor [automobile], ve kterém se snažíme určit, které proměnné ovlivňují spotřebu různých typů automobilů. Protože v původním souboru pocházejícím ze Spojených států se spotřeba vyjadřuje v mílích ujetých s jedním galonem, vytvoříme nejprve proměnnou spotreba, ve které je spotřeba uvedena klasicky v litrech na 100 km. Poté celý datový rámec připojíme.
automobile <- read.table("automobile.txt", header=TRUE,sep=",")
automobile$spotreba <- 1/automobile$mpg * 3.78541178/1.609344 * 100
attach(automobile)
Vytvoříme jednoduchý model, který se snaží spotřebu predikovat pomocí hmotnosti automobilu (v librách, spojitý prediktor) a země původu automobilu (americký automobil vs. zahraniční automobil, kategoriální prediktor).
model1 <- lm(spotreba ~ weight+foreign)
summary(model1)
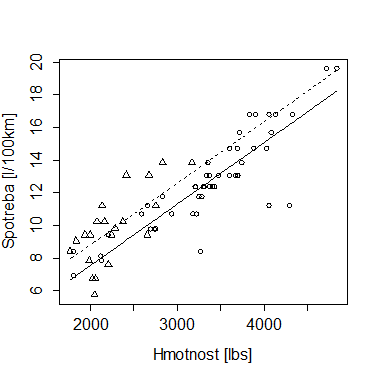
Na následujícím obrázku je znázorněno, jak vypadají na x-y grafu pozorované hodnoty pro americké (kolečka) a zahraniční (trojúhelníčky) automobily, a jak vypadají predikované hodnoty odpovídající příslušné hmotnosti pro americké (plná čára) a zahraniční (čárkovaná čára) automobily.
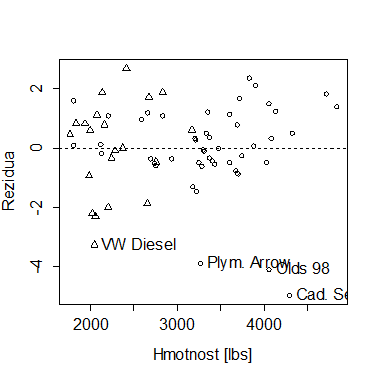
Nyní vykreslíme graf reziduí dle hmotnosti (nezávisle proměnné). Nyní se již zřetelně ukazují ta pozorování, u kterých je predikce vzdálena skutečné hodnotě a u kterých tedy navržený model selhává (na následujícím obrázku – pozorování s popiskem). Dokážete je najít i na předchozím obrázku?
plot(resid(model1)~weight,
xlab = "Hmotnost [lbs]",
ylab = "Rezidua",
ps=15, pch=c(1,2)[foreign]
)
abline(0,0,lty=2)
text(weight[abs(resid(model1))>3],resid(model1)[abs(resid(model1))>3],
make[abs(resid(model1))>3],pos=4)
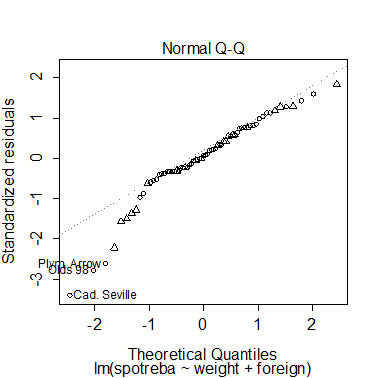
Q-Q diagram reziduí nám tato pozorování rovněž ukazuje jako ta, která znatelně porušují předpoklad o normálním rozdělení reziduí.
V neposlední řadě je vždy vhodné zjistit, nakolik jsou odlehlé hodnoty i vlivnými pozorováními. Užitečným nástrojem pro tento účel jsou zmíněné Cookovy vzdálenosti.
plot(cooks.distance(model1)~weight,
xlab = "Hmotnost [lbs]",
ylab = "Cookova vzdálenost",
ps=15,pch=c(1,2)[foreign]
)
text(weight[abs(cooks.distance(model1))>0.1],
cooks.distance(model1)[abs(cooks.distance(model1))>0.1],
make[abs(cooks.distance(model1))>0.1],pos=4)
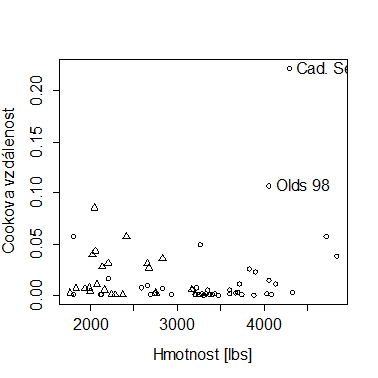
Ukazuje se, že přinejmenším jedno pozorování (Cadillac Seville) významně ovlivňuje výsledný model, je zcela atypické. Z předchozí analýzy je zřejmé, že se jedná o auto s poměrně vysokou hmotností, ale relativně nízkou spotřebou. Při další analýze by tedy bylo vhodné zjistit více detailů o tomto automobilu nebo zahrnout do analýzy více proměnných (např. proměnné související s typem motoru, aerodynamikou, apod.).


{kind=link}