Popis a vizualizace kvalitativních dat
Označme zaznamenané hodnoty sledovaného znaku u výběrového souboru
subjektů. U kvalitativních dat předpokládáme opakování pozorování jednotlivých hodnot daného znaku, proto je logické sumarizovat tato data pomocí tabulky s četnostmi možných hodnot (tabulka četností, frequency table). Označíme-li
možné hodnoty sledovaného znaku, pozorovanou (absolutní) četnost odpovídající variantě znaku
budeme označovat jako
. Pro lepší orientaci a možnost srovnání je vhodné doplnit pozorovanou četnost i relativní četností, která má pro variantu znaku
tvar
.
Příklad 1. Sledujeme přítomnost diabetu u pacientů zdravotnického zařízení za období jednoho roku s tím, že rozlišujeme pacienta bez diabetu a pacienty s diabetem 1. nebo 2. typu ( = 3). Celkem bylo pozorováno
= 687 pacientů, sumarizaci výsledků uvádí tabulka 2.1.
Tabulka 2.1: Počty pacientů ve zdravotnickém zařízení dle přítomnosti diabetu
 |
Vzhledem k tomu, že kvalitativní data často nelze seřadit dle velikosti, používá se jako frekvenční charakteristika těchto dat tzv. mód (mode), což je varianta znaku s největší četností. V příkladu 1 je modální hodnotou pacient bez diabetu. Vypovídací hodnota módu jako reprezentanta pozorovaných dat závisí především na počtu kategorií sledovaného znaku a vyrovnanosti jejich četností. Někdy může být mód opravdu typickou hodnotou, jindy mohou být četnosti jednotlivých variant znaku tak vyrovnané, že to spíše indikuje neexistenci typické hodnoty pro daný znak.
V případě nízkých pozorovaných četností některých kategorií je často vhodné tyto kategorie sloučit a dále pracovat již pouze se sloučenými kategoriemi. Slučovat by se však měly pouze příbuzné (nebo po sobě následující v případě seřaditelných kategorií) kategorie a ještě pouze v případě, kdy jejich sloučení zachovává data interpretovatelnými (příkladem mohou být hierarchické kategorizace jako je mezinárodní klasifikace nemocí, kdy namísto detailních podkategorií diagnózy je možné použít danou diagnózu souhrnně nebo stádia onemocnění, kdy namísto detailních stádií I, II, III, IV dává v řadě případů smysl sloučení I+II, III+IV apod.).
Pro vizualizaci kvalitativních dat se nejčastěji používají sloupcový graf (bar plot) a výsečový neboli koláčový graf (pie chart), kde výška sloupců (šířka je pro všechny sloupce stejná), respektive plocha výsečí, pro jednotlivé varianty je úměrná jejich četnosti. U koláčového grafu jeho plocha představuje 100 %, proto je vhodný pro vizualizaci relativních četností, ve sloupcovém grafu můžeme zobrazit obojí, jak absolutní, tak relativní četnosti. Příklad sloupcového a koláčového grafu s absolutními a relativními četnostmi z tabulky 2.1 je uveden na obrázku 2.1.
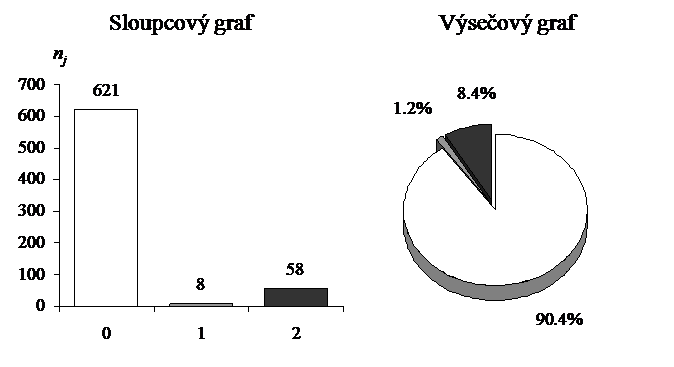 |
Obr. 2.1: Příklad sloupcového a výsečového grafu na datech z tabulky 2.1.
