Sestavení sekvence
Sestavení celého genomu (genome assembly) anebo jednotlivé sekvence (kontig z anglického contig) vzniká z postupných kroků podle úrovně aktuálních znalostí. Nejdřív se pro jednotlivá čtení určí jejich směr (F nebo R) a seřadí se tak, aby jejich sekvence maximálně vzájemně odpovídala. Takto sestavená sekvence je kontig. Po případných ručních opravách kontigu se sestaví sekvence z nejčastěji se vyskytujících nukleotidových bází v jednotlivých pozicích – konsenzuální sekvence.
Pokud z kontigů potřebujeme sestavit celý genom, v dalším kroku se analyzuje, v jakém pořadí kontigy za sebou následují. Toto je v genomech komplikované kvůli výskytu repetitivních sekvencí a tak se laboratorními metodami zjišťuje, jak daleko od sebe se kontigy vyskytují a ke kterému řetězci patří. Sekvence, kde známe pořadí nukleotidů v některých úsecích a víme, jak daleko od sebe osekvenované úsek jsou, ale už ne jaká je mezi nimi sekvence, se jmenují superkontigy (anglicky také scaffold).
Kontig se sestavuje vždy ze čtení z jednoho jedince. Jeho výsledkem má být reálně existující sekvence DNA. Porovnání sekvencí více jedinců je alignment.
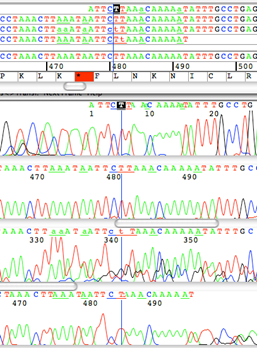
Pro sestavení sekvence ze Sangerova sekvenování platí, že přímý výstup ze sekvenátoru jsou obrázky, které zachycují změnu intenzity světelného signálu a jmenují se chromatogramy. V závislosti na úspěšnosti sekvenační reakce můžou být chromatogramy různě čitelné a zpracovávat by se měly jenom ty s kvalitním signálem (obr. 1), aby se do konsenzuální sekvence nevkládaly chyby v sekvenování, které by následně mohly být vyhodnoceny jako mutace (obr. 2).