Scenáře ancestrálních stavů
Výpočet věrohodnosti začíná při výpočtu pravděpodobnosti, jakou nukleotidovou bázi měl nejbližší společný předek dvou sekvencí (TMRCA, obr.1). Z abecedy x = {A,C,G,T} se mohla každá báze vyskytovat u TMRCA, ale s různou pravděpodobností. Na příkladu, kde dva taxony mají v sledované pozici alignmentu tymín a cytozín, bude pravděpodobnost, že jejich předek měl adenin vypočtena na základě substitučního modelu. Pravděpodobnosti, s jakou bude adenin vybranou bází v alignmentu, pravděpodobnosti, že adenin zmutoval na tymin u první sekvence a pravděpodobnosti, že adenin zmutoval na cytozin u druhé sekvence. Obdobně výpočet probíhá za předpokladu dalších možností ancestrálních stavů.
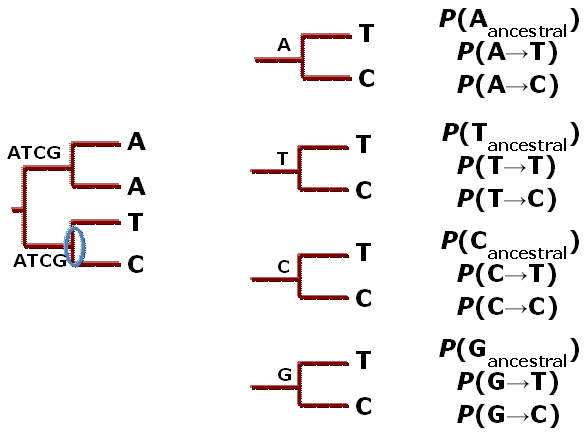
Obr. 1: Scénáře ancestrálních stavů jednoho uzlu fylogeneze pro jednu pozici alignmentu. Výpočet pravděpodobnosti pro jednotlivé možné stavy vychází ze substitučního modelu.
