Datový typ Pole
K čemu může sloužit proměnná typu pole si ukážeme na řešení problému s průměrem známek studenta. Nyní ale budeme nejprve chtít všechny známky uložit a pak teprve zpracovávat. První co Vás napadne bude patrně to, že si vytvoříme proměnné znamka1, znamka2, znamka3, znamka4... Problém ale bude v tom, že nevíme kolik těchto proměnných máme vlastně vytvořit. Co když vytvoříme proměnné jenom pro 10 známek ale posléze jich bude potřeba 15? K tomuto účelu právě použijeme pole. Uložíme více dat (většinou stejného typu) pod jednu proměnnou a rozlišíme je pomocí indexů. Místo proměnných znamka1, znamka2, znamka3, znamka4... tak budeme mít pouze jednu proměnnou znamka.
Proměnnou můžeme chápat jako námi zvolený název, kterému se v průběhu překladu nebo běhu programu přidělí paměť. Je to tedy tak, že námi zvolený název proměnné je jakýsi ukazatel na adresu v paměti. Vytvoříme-li proměnnou A, tak vlastně máme takový šuplíček, na kterém je napsáno "A" a který obsahuje hodnotu proměnné A. Přiřazením hodnoty 5 do proměnné A vlastně provedeme to, že otevřeme daný šuplíček a vložíme do něj hodnotu 5.
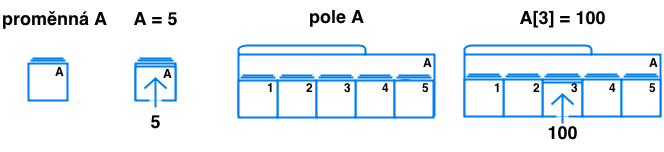 |
Na pole se můžeme dívat jako na skupinu takových šuplíčků v jednom rámu, který je drží všechny pohromadě a nese název proměnné (tj. na rámu je napsáno "A"). Pokud chceme pracovat s polem jako celkem, tak se na něj odkazujeme jménem pole (A). Pokud chceme pracovat s jednotlivými položkami pole (šuplíčky), tak musíme použít index pro přistup k jednotlivým šuplíčkům. To znamená, že pokud chceme vložit hodnotu do jednoho z šuplíčků pole, tak se na něj musíme odkázat - musíme ho zaindexovat.
Index je vlastně pořadové číslo šuplíčku v daném poli. Každý šuplíček má svůj index na sobě napsaný. Indexace se zapisuje jako číslo v hranatých závorkách za jménem proměnné. V případě našeho pole jménem A, které má 5 šuplíčků, se k jednotlivým položkám (šuplíčkům) přistupuje A[1], A[2], A[3], A[4], A[5]. Chceme-li do 3. šuplíčku pole A zapsat hodnotu 100, tak napíšeme A[3] = 100.
Poznámka: jak to tak bývá, tak ani zde není vše jednoznačné. My nyní budeme používat indexování od 1. Některé programovací jazyky ho také používají, jiné mají indexování od 0, v jiných lze rozmezí indexů definovat.
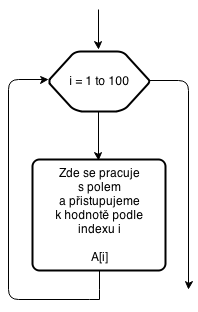
K procházení pole budeme používat cykly (většinou) s daným počtem opakování.. Využijeme k tomu index, který v tomto cyklu používáme. Cyklus tak bude (vždy) od 1 do velikosti pole. A v jednotlivých průchodech budeme přistupovat k jednotlivým šuplíčkům pole. Fragment vývojového diagramu, tak jak jej budeme používat, je na následujícím obrázku.
 |
Rozlišení, že jde o pole provedeme zápisem klíčového slova array a hranatých závorek (array[]). Pokud budeme vědět, s jak velkým polem budeme pracovat, tak do hranatých závorek zapíšeme tuto velikost. V případě, že neznáme, jak velké bude výsledné pole, tak necháme hranaté závorky prázdné. První typ (se známou velikostí pole) je staticky definované pole - velikost známe v době tvorby programu. Druhý typ je pole s dynamickou velikostí pole - velikost pole se mění dle aktuálních potřeb v programu. Pole může být samozřejmě libovolného typu, takže můžeme mít pole 4bajtových celých čísel, pole desetinných čísel atd. Pokud budeme chtít určit typ prvků v poli, tak tento typ zapíšeme za definici pole (např. x: array[] of integer).
