Optimální volba predikční funkce g
Pomocí regresní a korelační analýzy lze provádět predikce nejrůznějšího typu. Nejzávažnější otázkou je, jak volit vhodnou predikční funkci .
platí
a rovnost v uvedené nerovnosti nastává právě když
- Nechť
jsou náhodné veličiny a
jsou reálné konstanty, pak pokud střední hodnoty
existují, platí
| (1) |
- Nechť
jsou náhodné veličiny a střední hodnota
existuje, pak
|
|
(2) |
a rovnosti je dosaženo tehdy a jen tehdy, když existují reálné konstanty
, kde
tak, že
přičemž
pro
a
pro
.
Z těchto vlastností plyne, že je vhodnou mírou těsnosti lineárního vztahu náhodných veličin
.
Věta 2.4. Mějme náhodnou veličinu s konečným a nenulovým rozptylem a náhodný vektor
. Potom
pro libovolnou měřitelnou funkci
| (1) |
Z první věty plyne, že nejlepší predikci náhodné veličiny V této souvislosti potom nejlepší prediktor |
| (2) | Z druhé věty plyne, že regresní funkce |
| (1) |
Z předchozích vět plyne, že a tedy pro korelační poměr platí nerovnost |
|
| (2) |
Po vydělení rovnosti (14) rozptylem Označme symbolem pak díky předchozímu máme Z tohoto vztahu plyne velice názorná interpretace korelačním poměru |
|
| (a) | Je-li střední kvadratická chyba predikce |
|
| (b) | V druhém krajním případě, když střední kvadratická chyba predikce je rovna |
|
Tedy korelační poměr poskytuje míru přesnosti predikce a je velice užitečný při srovnávání různých vektorů doprovodných proměnných.
Poznámka 2.7. (polopatě). Vysvětleme si předchozí pojmy pomocí následujícího obrázku.
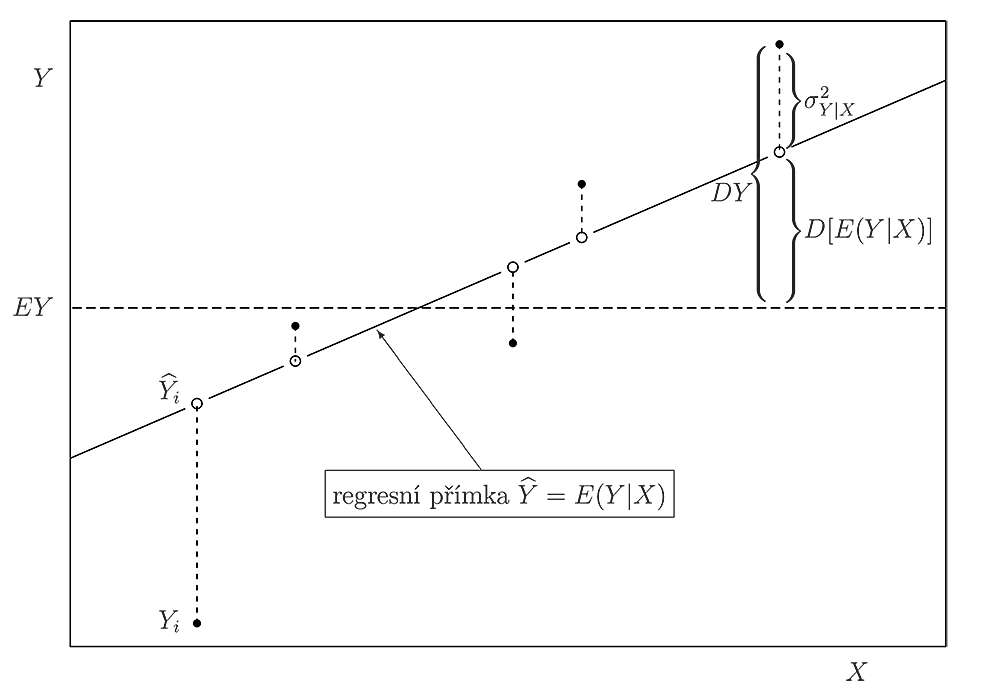
Příklad 2.9. Při laboratorním pokusu bylo získáno následujících 8 výsledků měřeníZvolený model nám predikoval tyto hodnotyUrčete index determinace a interpretujte ho.Řešení. Ukážeme oba způsoby výpočtu. Vypočteme nejprve příslušné výběrové rozptyly:Podle definice jeneboVýsledek lze interpretovat tak, žecelkové variability je vysvětleno zvoleným modelem.
1 Karl Pearson (1857 - 1936). Britský statistik a matematik. Studoval na Cambridge a poté působil na univerzitě v Londýně. Vychoval řadu vynikajících statistiků.
